Machine Learning: Scaled Dot-Product Attention
Scaled Dot-Product Attention
cite Attention_Is_All_You_Need
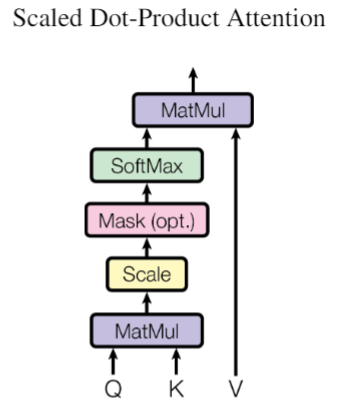
We call our particular attention “Scaled Dot-Product Attention”. The input consists of queries and keys of dimension $dk$, and values of dimension $dv$. We compute the dot products of the query with all keys, divide each by $\sqrt{dk}$, and apply a softmax function to obtain the weights on the values. In practice, we compute the attention function on a set of queries simultaneously, packed together into a matrix Q. The keys and values are also packed together into matrices K and V. We compute the matrix of outputs as:
In practice, we compute the attention function on a set of queries simultaneously, packed together into a matrix Q. The keys and values are also packed together into matrices K and V . We compute the matrix of outputs as:
$$Attention(Q,K,V) = softmax(\frac{QK^{T}}{\sqrt{d_{k}}})V$$
以上公式中Q代表了query,K代表了keys,V代表了values,$d_k$代表了keys的维数。
理解:$QK^T$代表了Q和T的相似部分,亦或着说是利用Q来对K的某一部分进行关注(Attention),然后这一结果利用softmax函数进行归一化,中间的除以$\sqrt{d_k}$感觉没有太大的意义,只是为了使得结果的差距没那么大,将结果压缩了一下而以,图中的Mask部分还没有找到对应的解释。最后用这归一化后的概率对V进行加权。